

代码拉取完成,页面将自动刷新
作者:赛鸭脖团队
前端开源链接:https://gitee.com/bchena/smart
项目演示视频:赛博智评——智能阅卷平台
阅卷辅助平台应用:
本项目是基于 Spring Security + MQ + Redis 结合深度学习技术实现智能化评阅的阅卷平台。系统以智能评阅为核心,提供题组管理、任务分配、智能评分、个性评语、学情分析和知识延展等功能,实现评阅全流程智能化的解决方案。
主要包含三大角色:阅卷科目组长、阅卷老师、学生。

为提升模型训练的质量,通过PPOCRLabel对12w数据集进行标注,再进行数据清洗、数据增强、划分训练集和测试集。这样在模型训练的时候提高数据集质量,使模型更好的收敛。此外添加了中科院将近33w高质量数据集,以提升模型训练质量。
选择PPOCRv4-rec-server文本识别训练模型进行训练,选用配置文件hgent-fp32.yml。这个尽量选择更大的内存(批次大小为128或者256)和精度训练(fp32精度)这使得模型训练速度加快、各项指标提升
选择优化器Adam和动态学习率CosineAnnealingIR (前期降低学习率,后期增加学习率,可以使模型更好的收敛、增加模型的泛化能力),并使用了l2正则化,防止了模型过拟合。
选用SVTR算法和PP-HGnet-small 骨干结构,SVTR系列的预测精度和正确率效果达到了82.5%
预测结果predict.py中加入半角、全角符号替换,进行字典错字替换来提高结果正确率。本项目中使用将近7000个错字替换,使得预测准确率至少提升2%
| 技术 | 作用 | 版本 |
|---|---|---|
| @toast-ui/vue-image-editor | 图片处理组件 | 3.15.2 |
| axios | 发送ajax请求给后端进行交互 | 1.6.5 |
| jQuery | 提供了强大的功能函数 | 3.7.1 |
| core-js | 兼容性更强 | 3.8.3 |
| default-passive-events | Chrome增加了新的事件捕获机制Passive Event Listeners(被动事件监听器),让页面滑动更加流畅 |
2.0.0 |
| echarts | 支持多种类型和效果的数据可视化图表 | 5.5.0 |
| gasp | 动画库 | 3.12.4 |
| localforage | 本地存储较大文件 | 1.10.0 |
| sass | css3的拓展,减少css重复的代码 | 1.69.7 |
| vue-router | vue官方的路由管理器,使单页面应用实现变得更容易 | 3.0.1 |
| vuex | 状态管理 | 3.0.1 |
| element-ui | 模块组件库,绘制界面 | 2.15.14 |
| vue | 提供前端交互 | 2.7.16 |
| 技术 | 作用 | 版本 |
|---|---|---|
| JDK | Java开发工具包 | 1.8 |
| SpringBoot | 应用开发框架 | 2.7.3 |
| SpringSecurity | Spring安全框架 | 2.7.3 |
| Mysql | 提供后端数据库 | 8.0.33 |
| Redis | 刷新令牌、缓存数据 | 2.1.7.RELEASE |
| Lombok | 快速生成实体类方法 | 1.18.20 |
| MybatisPlus | ORM框架,连接数据库 | 3.4.2 |
| Hutool | 提供实用性工具类 | 5.7.17 |
| Jackson | 提供JSON解析工具类 | 2.11.4 |
| Junit | 提供单元测试功能 | 3.8.1 |
| jwt | token工具包 | 0.9.0 |
| aliyun-sdk-oss | 阿里云对象存储 | 2.8.3 |
| commons-compress | 支持多种解压方式 | 1.21 |
| RabbitMQ | 提供消息队列服务 | 2.7.3 |
| 技术 | 作用 | 版本 |
|---|---|---|
| Gradio | Gradio是一个用于快速创建可分享的机器学习模型的Web应用界面的库。 | 3.5.0 |
| FastDeploy | FastDeploy是一个用于部署机器学习和深度学习模型的工具。 | 1.0.7 |
| ErnieBot | ErnieBot是一个预训练的自然语言处理模型,用于生成文本。 | 0.5.3 |
| 技术 | 作用 | 版本 |
|---|---|---|
| PPOCRLabel | 用于数据标注、文检测和识别,便于模型训练数据集 | PPOCRLabel v2(版本) |
| 卷积神经网络(CNN) | 特征提取:CNN能够自动学习图像中的特征,有卷积层、池化层、全连接层等结构 | 模型的底层架构(详细逻辑结构如下表) |
| 数据增强 | 增加数据多样性、实现数据量的扩大、减轻过拟合、提高模型的泛化能力。 | 包括了原始数据进行旋转、缩放、平移、翻转、裁剪等操作 |
| 文本识别算法(SVTR_HGNet) | 高效识别速度、准确识别文本、适用多种场景、扩展性强 | 包括了下面的特征提取器(CNN)、Neck架构、Head架构、损失函数、SVTR模块 |
| 主干网络(PPHGNet_small) | 进行模型创建、模型实例化、预训练模型加载、特征提取。 | 通常使用卷积神经网络(CNN) |
| 多头部结构(MultiHead) | 进行多任务处理、增加模型灵活性、共享底层特征提取器(卷积神经网络CNN)、方便模型训练和部署 | 包括CTCHead和NRTRHead,主要用到前向传播方法 |
| 多损失函数(MultiLoss) | 进行多任务学习、通过加权损失函数来加快模型训练、加速收敛、提高效率;多正则化、防止过拟合。 | 包括CTCLoss和NRTRLoss、这两种损失函数通过前向传播进行加权组合 |
| 模型后处理方法(PostProcess) | 将模型输出的预测结果转换为文本标签,并进行解码和后处理,以便进一步评估模型的性能或生成最终的识别结果。 | 主要是CTCLabelDecode解码和整合。 |
| 动态学习率(CosineAnnealingLR) | 通过动态调节学习率来增加模型对数据的适应能力、加快模型训练和收敛。 | 使用cosnie余弦退火周期、前期降低学习率,后期升高学习率。 |

本系统分为三个角色:阅卷科目组长、学生和阅卷老师,各角色功能如下图:


阅卷组长:
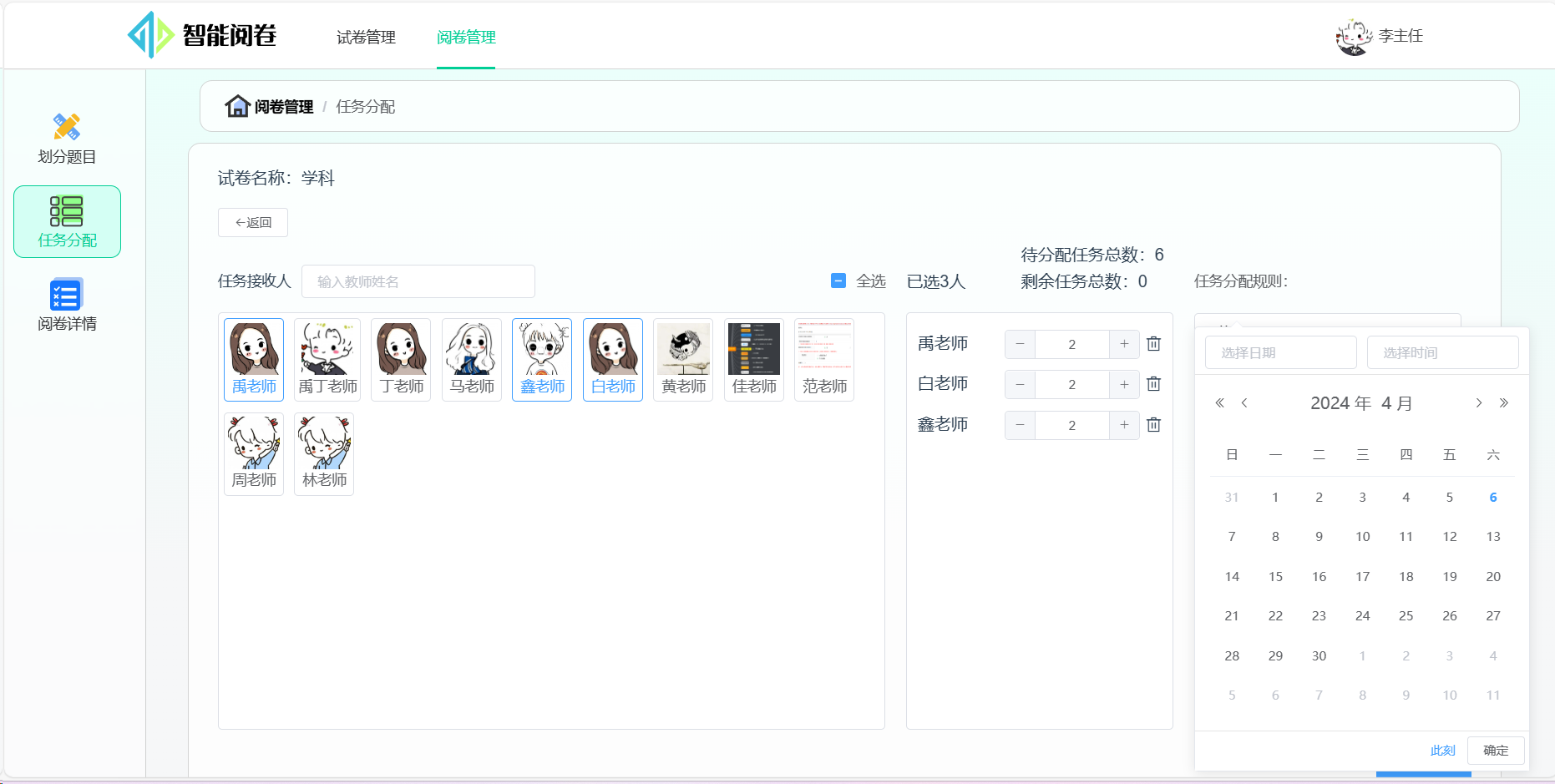
题组录入:上传试题和答题卡
划分题目:自主标记阅卷区域
分配任务:一键分配阅卷任务
阅卷老师:
智能评阅:AI批量评阅、评阅内容再编辑
多样评语:定义学生评价标签,生成个性化评语
学生:
查看结果:查阅评分细节、跟踪成绩情况
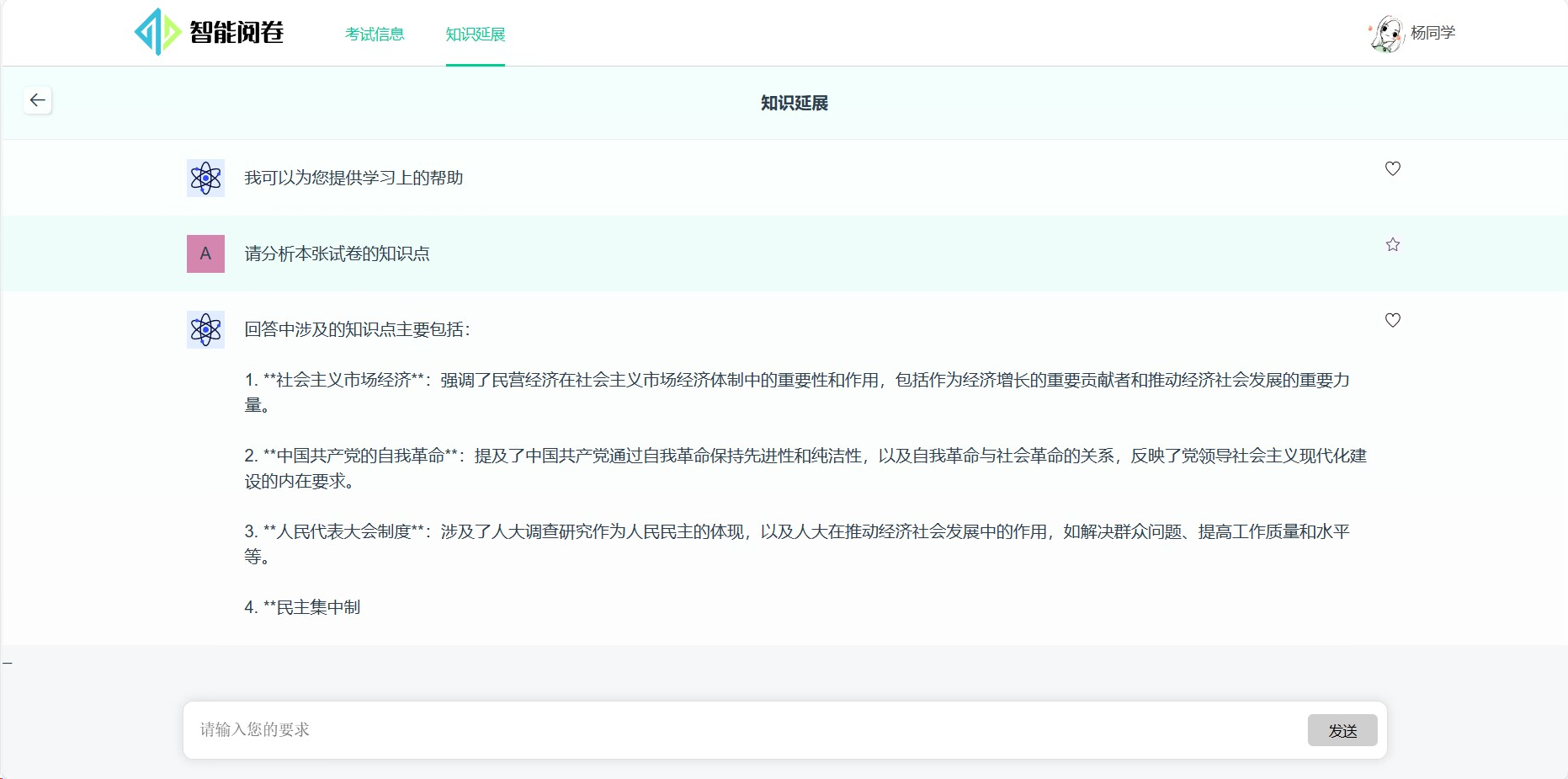
智能辅导:AI提供指导、进行知识回顾与拓展
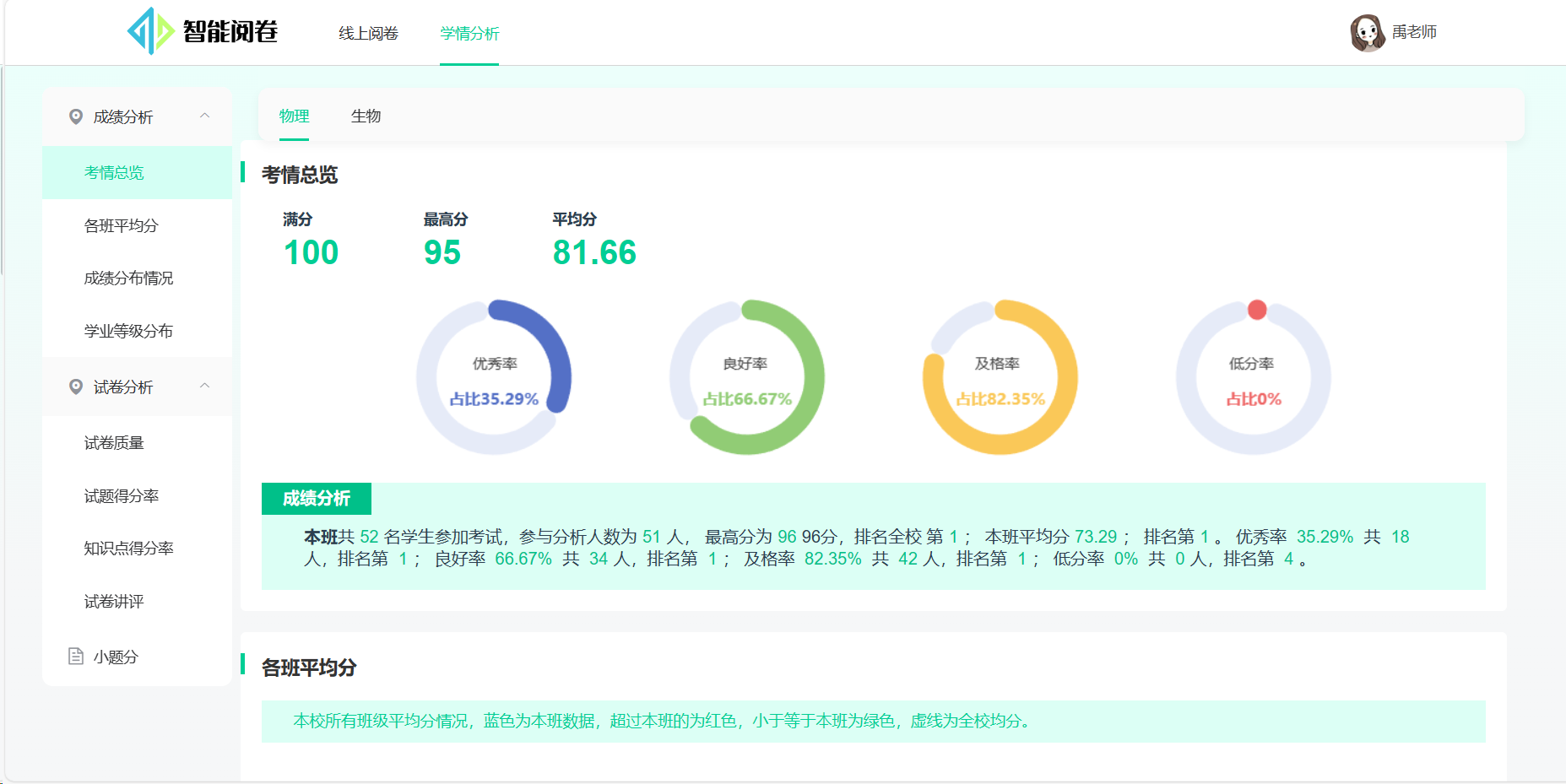
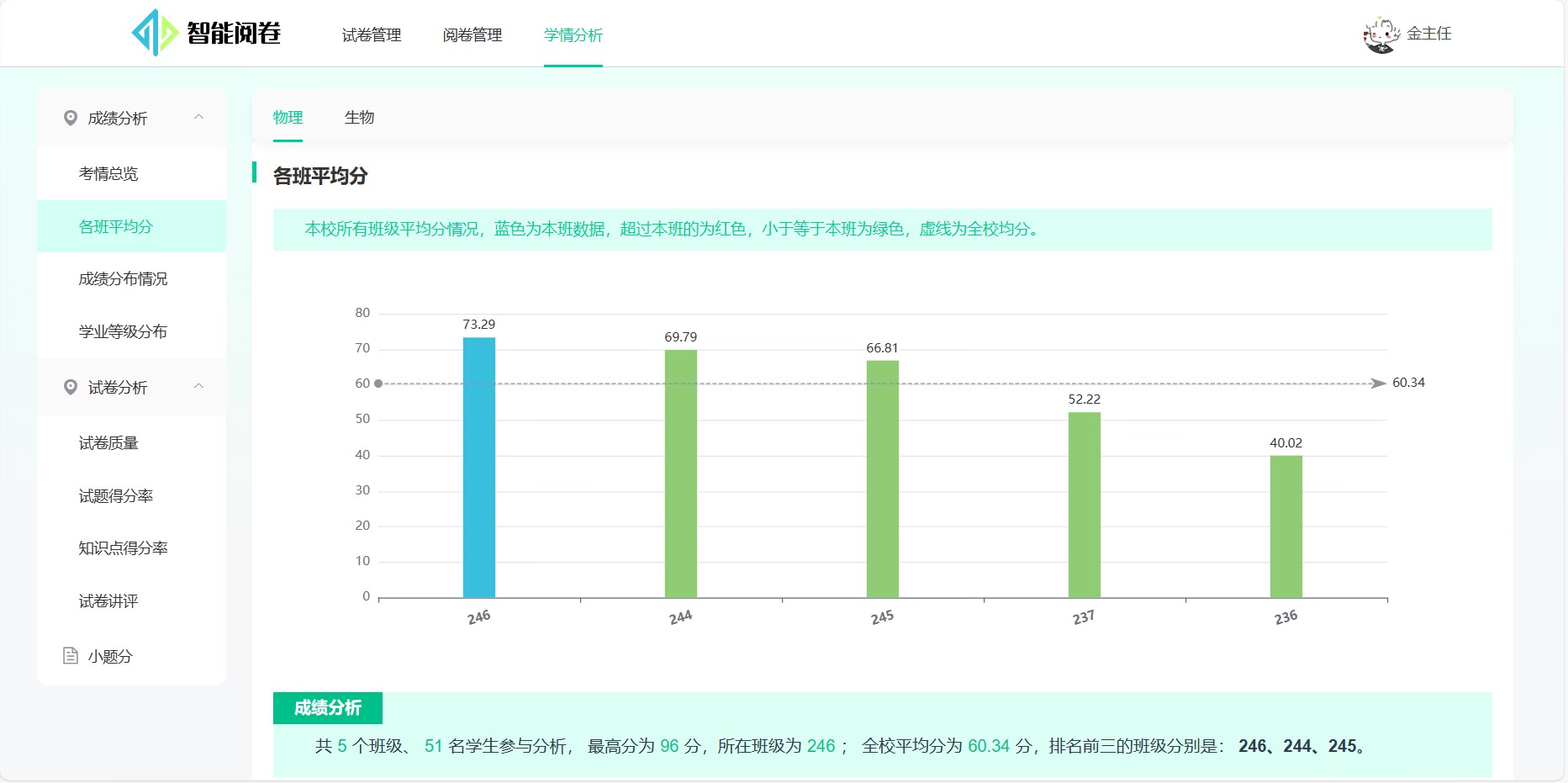
**学情分析:**阅卷组长和老师可查看成绩分布、题目质量、试题得分率等可视化图表,多维度跟踪团体和个体的学业情况。
当客户端发送请求时,首先由过滤器链(FilterChain)对于除用户登录注册外的请求进行过滤。对于用户进行登录操作时,由JWT进行token令牌签发,转发到客户端,当客户端后续访问服务端时需要携带token令牌,由JWT进行身份校验成功后方可通过请求。请求通过后,经由controller层进行请求转发并协调service层处理业务逻辑并返回数据到客户端,当请求需要使用模型时,service层将调用云端接口完成业务逻辑。Service层处理业务逻辑时,需要与数据层交互以从数据库中存储或取出数据,从而完成整个业务逻辑的流程。

当服务端接收到客户端的请求时,首先会判断该请求是否适合由Python来处理。如果Python不是必需的,服务端将直接与数据层交互,获取所需数据,并由服务层的业务逻辑进行相应处理。若请求确定需要Python参与,服务端会进一步判断是否需要调用Python模型。若无需调用模型,服务端会将请求数据设置为命令行参数,并调用本地的Python脚本来处理该请求。而若需调用Python模型,服务端则利用Hutool的HttpRequest类,通过封装formData数据发送请求,调用云端接口进行处理。在整个处理过程中,无论是本地处理还是云端处理,一旦处理成功,服务端将直接返回数据给客户端;若处理失败,则返回相应的错误信息。

当服务端需要检索数据时,服务层会与数据层进行交互以获取所需信息。在服务层提交查询请求后,系统会首先判断该请求是否为图片查询。若确定为图片查询请求,系统将转向阿里云OSS进行图片检索。若成功找到图片,则直接返回图片数据;若未找到,则返回相应的错误码。若查询请求非图片相关,系统首先会尝试从Redis缓存中检索数据。若缓存命中,则直接返回数据;若缓存未命中,则需进一步查询数据库。若数据库中仍无所需数据,则返回错误信息;若数据库中存在数据,则将该数据写入Redis缓存,并返回给服务层。

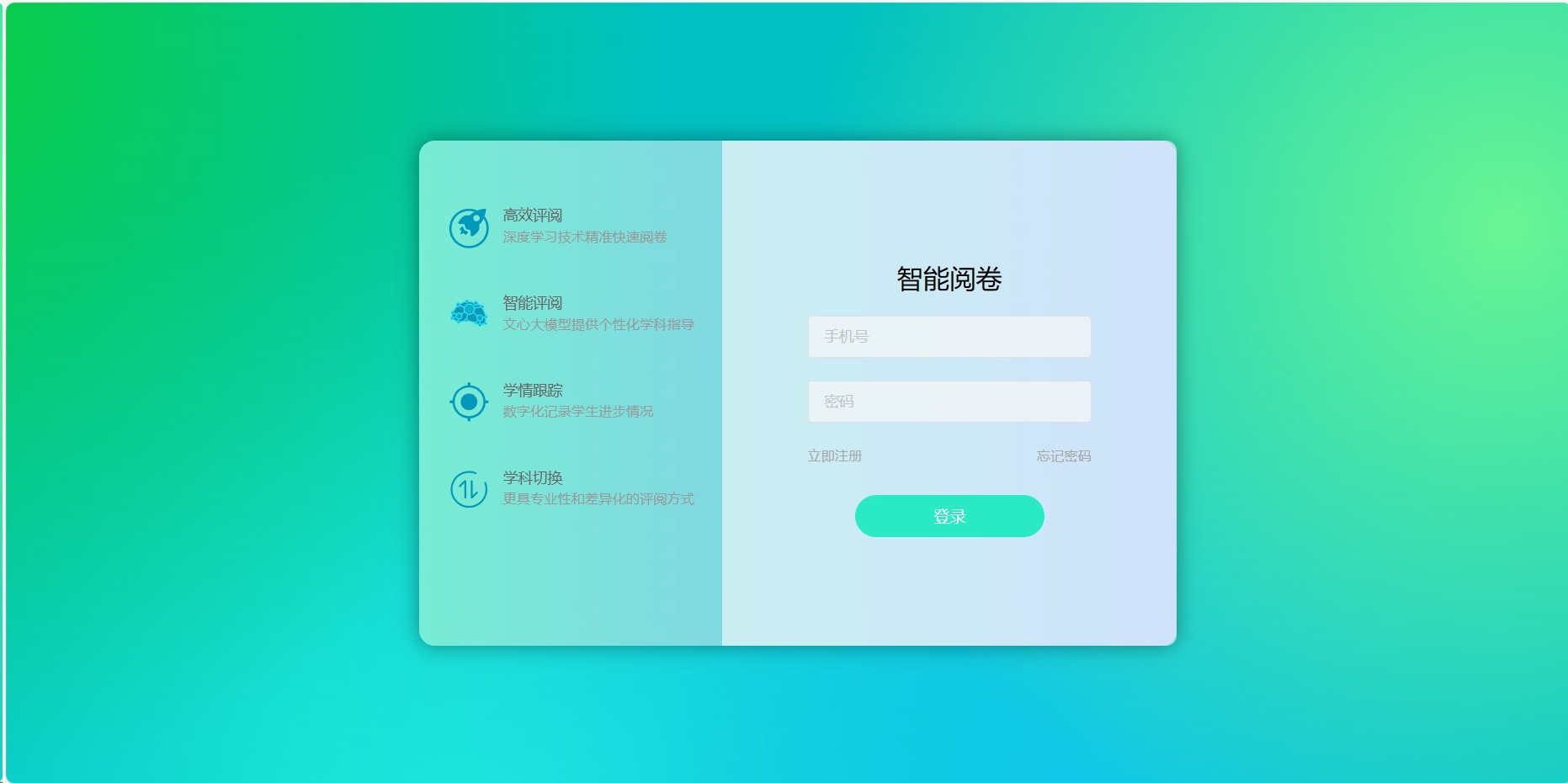
登录界面:
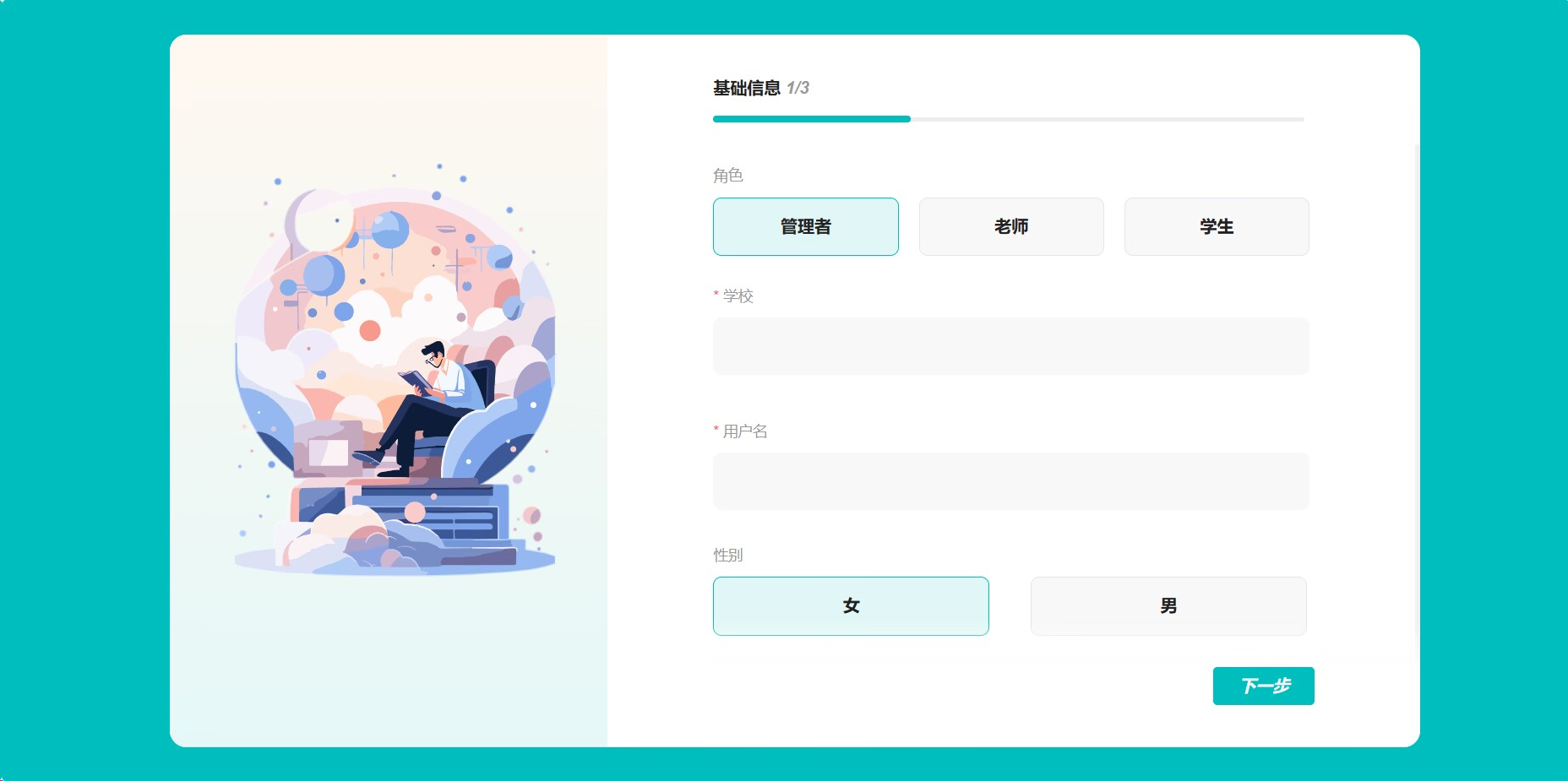
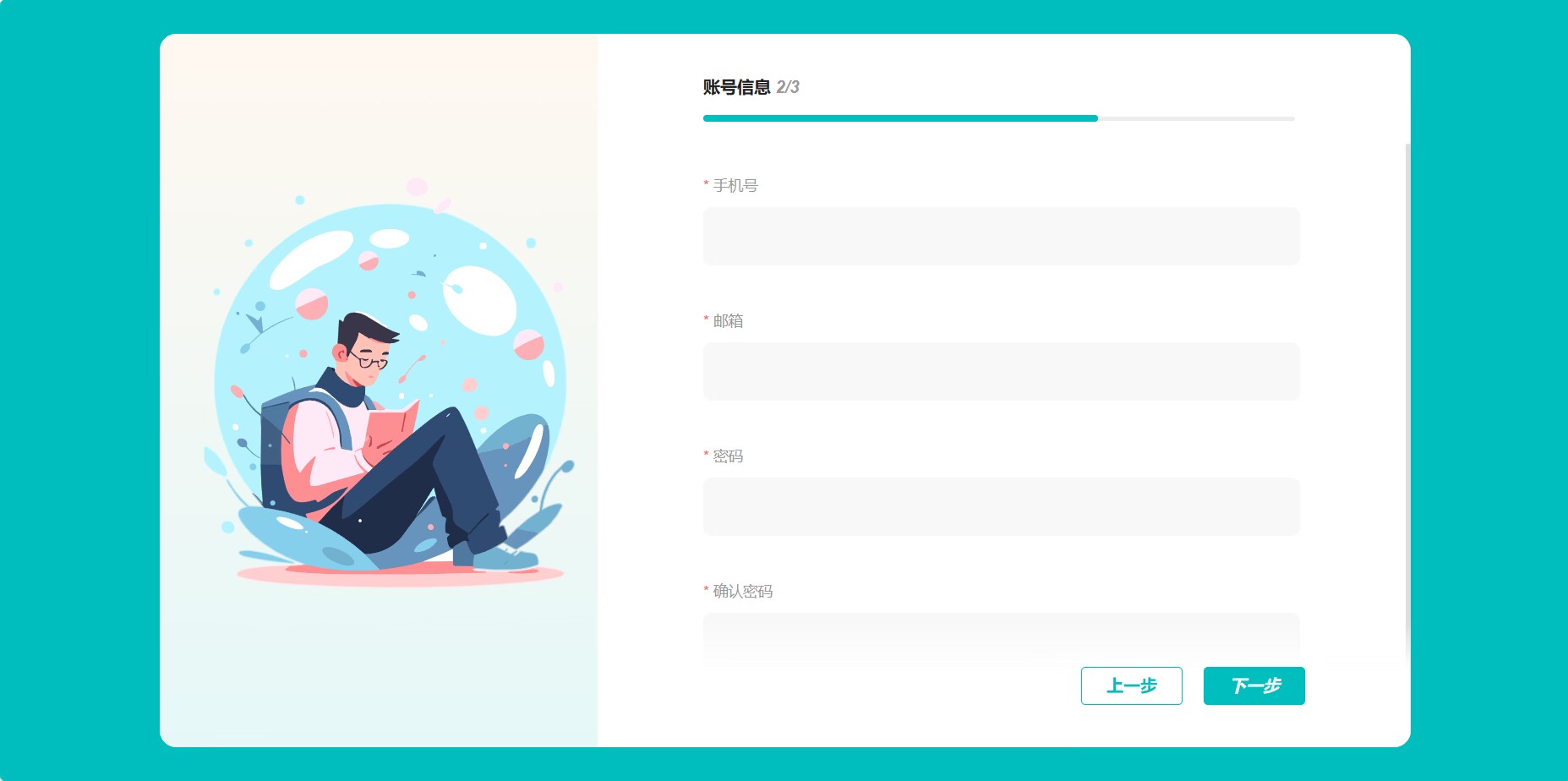
注册界面:
找回密码:
基本资料:
修改密码:
上传题组:

查看样卷:

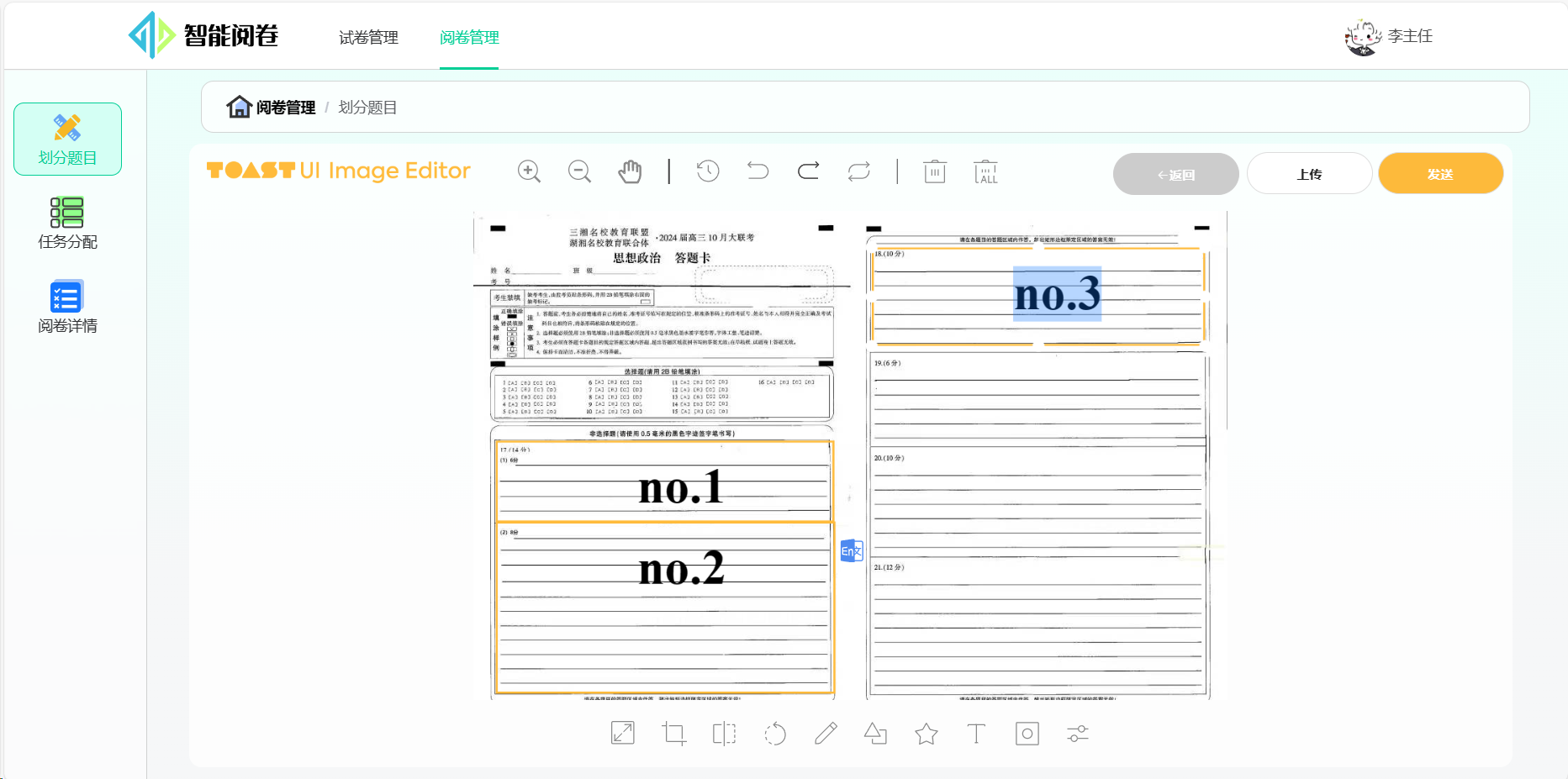

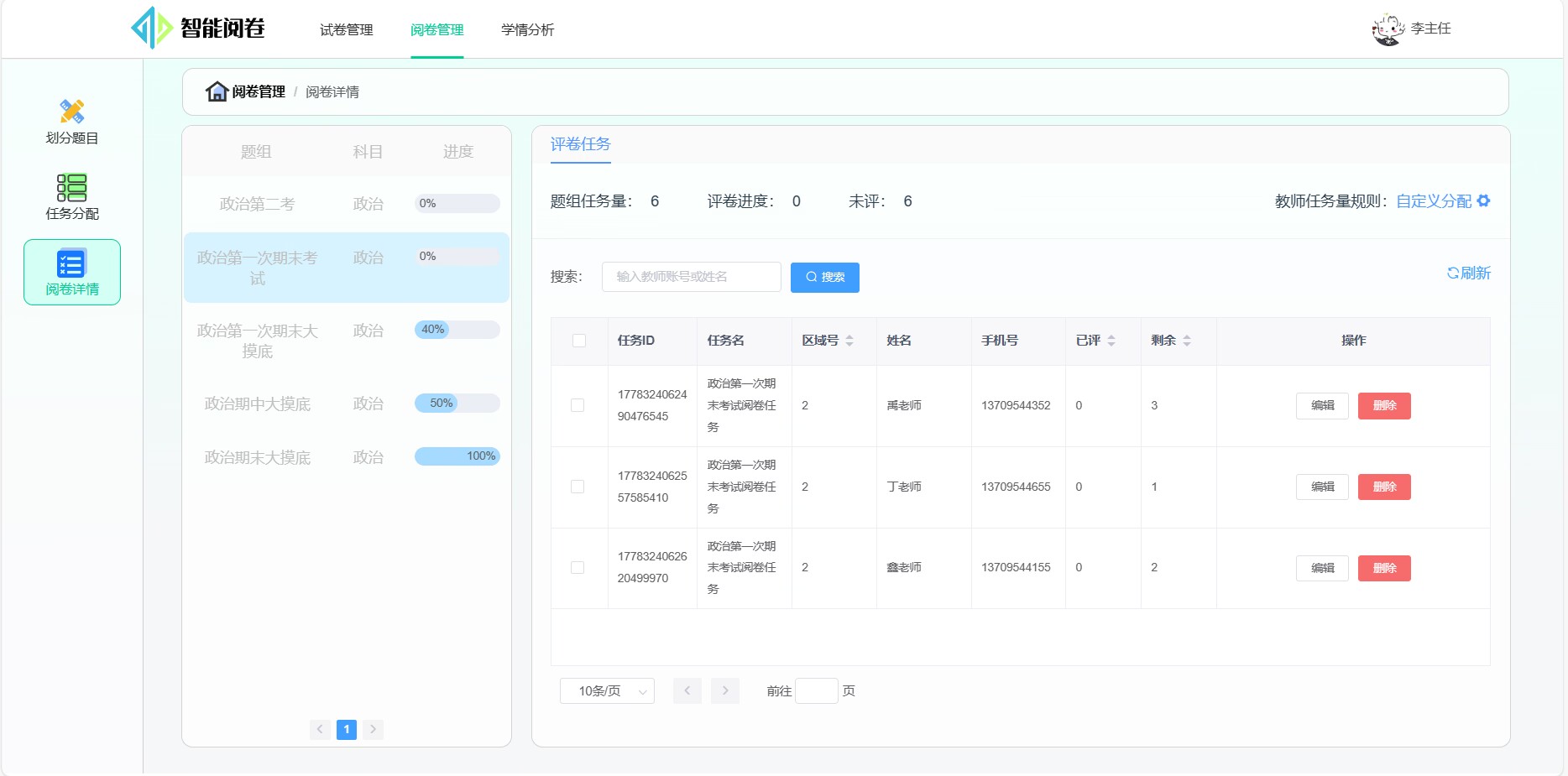
考情总览:
各班平均分:
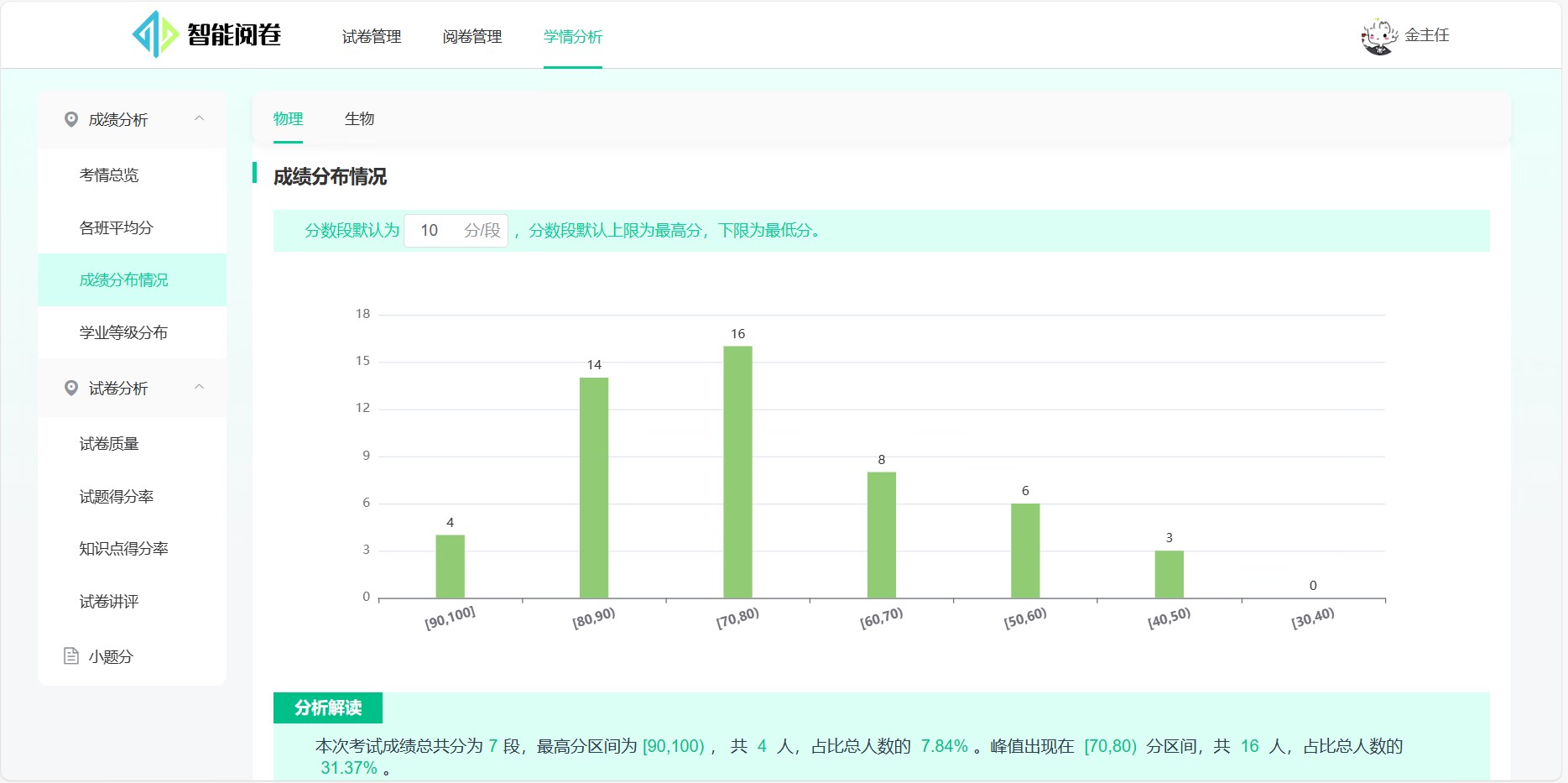
成绩分布情况:
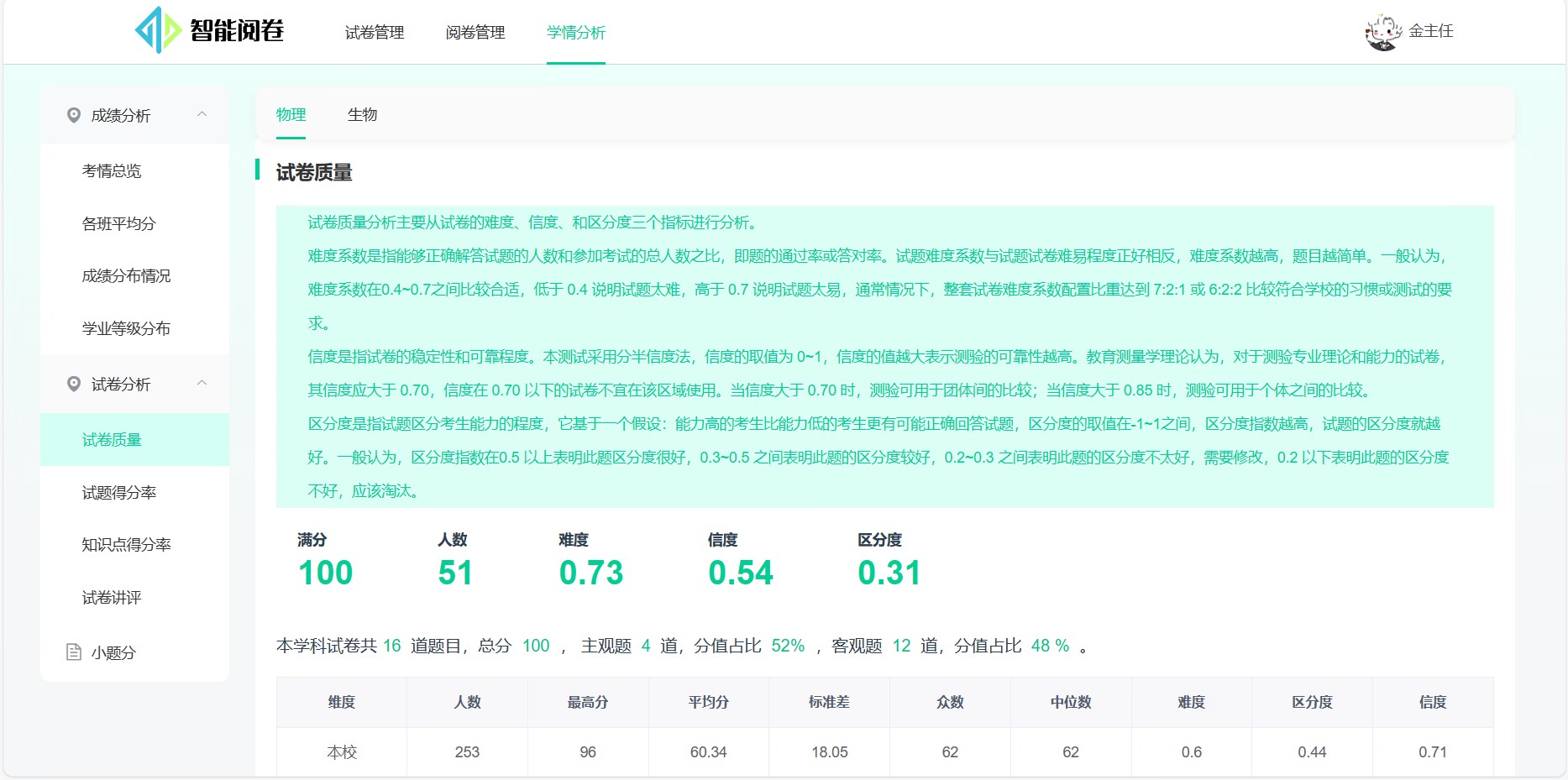
试卷质量:
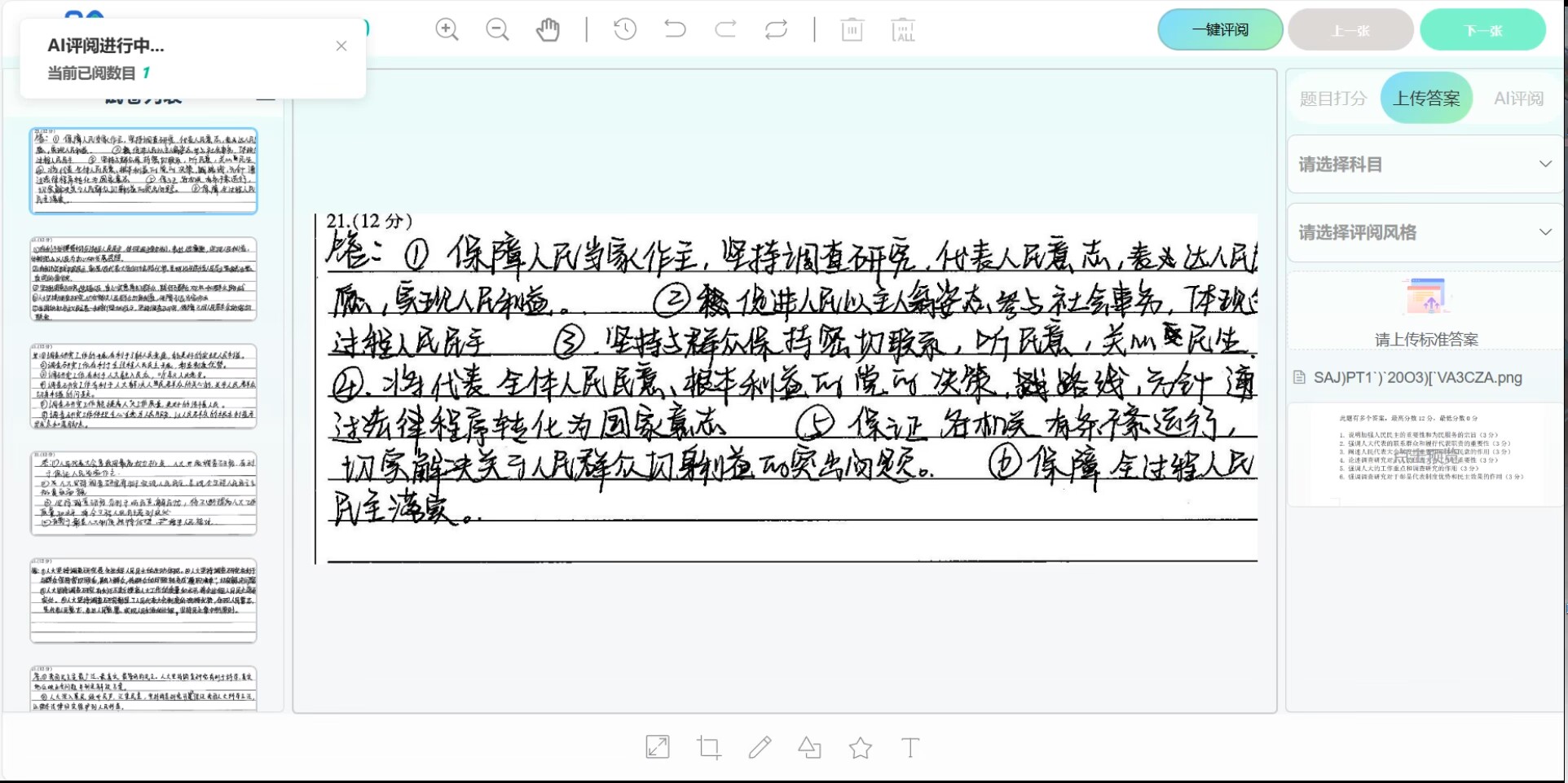
题目打分:

上传答案:

AI评阅:

一键提交:
选择标签:
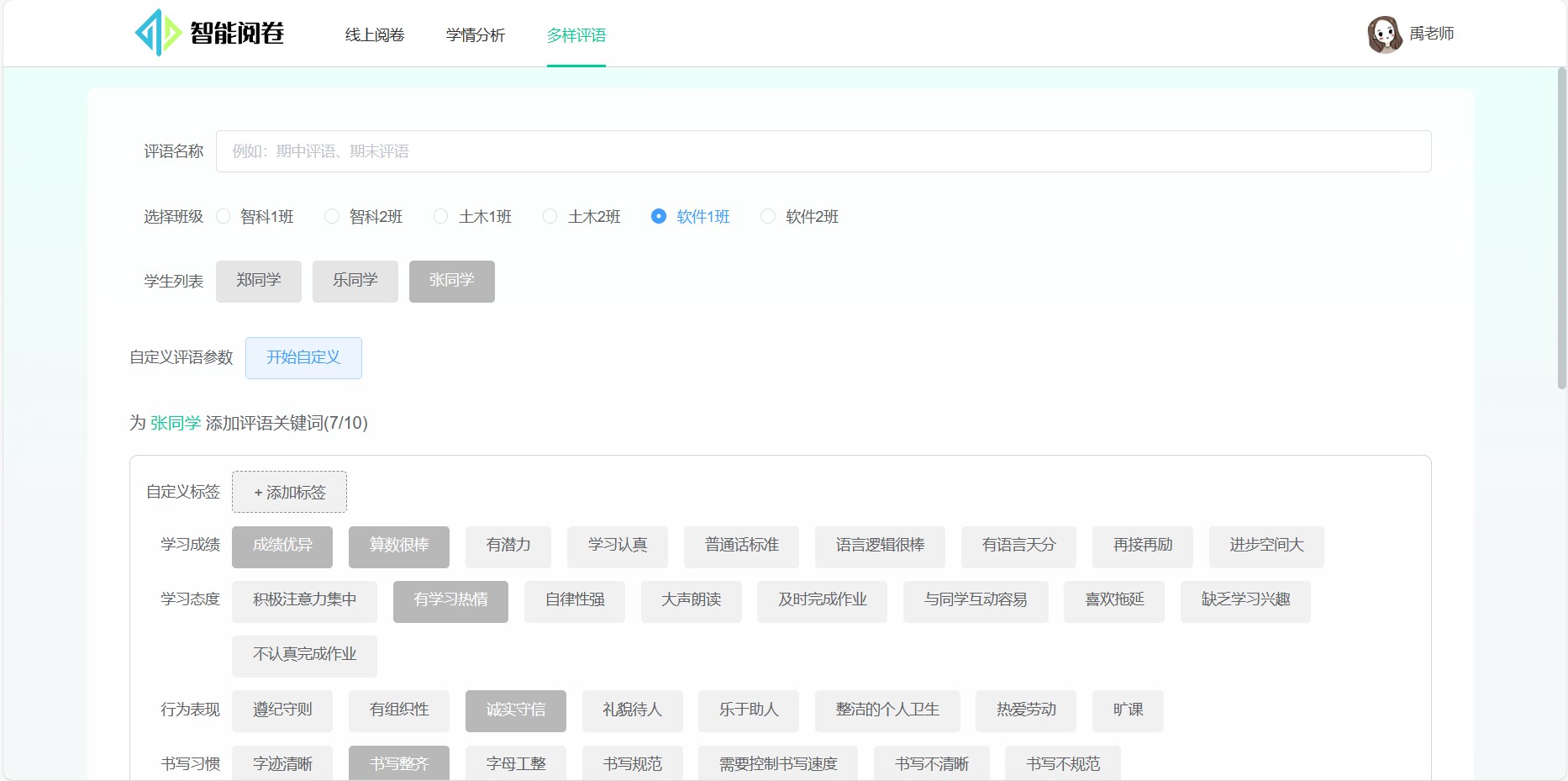
评语参数:
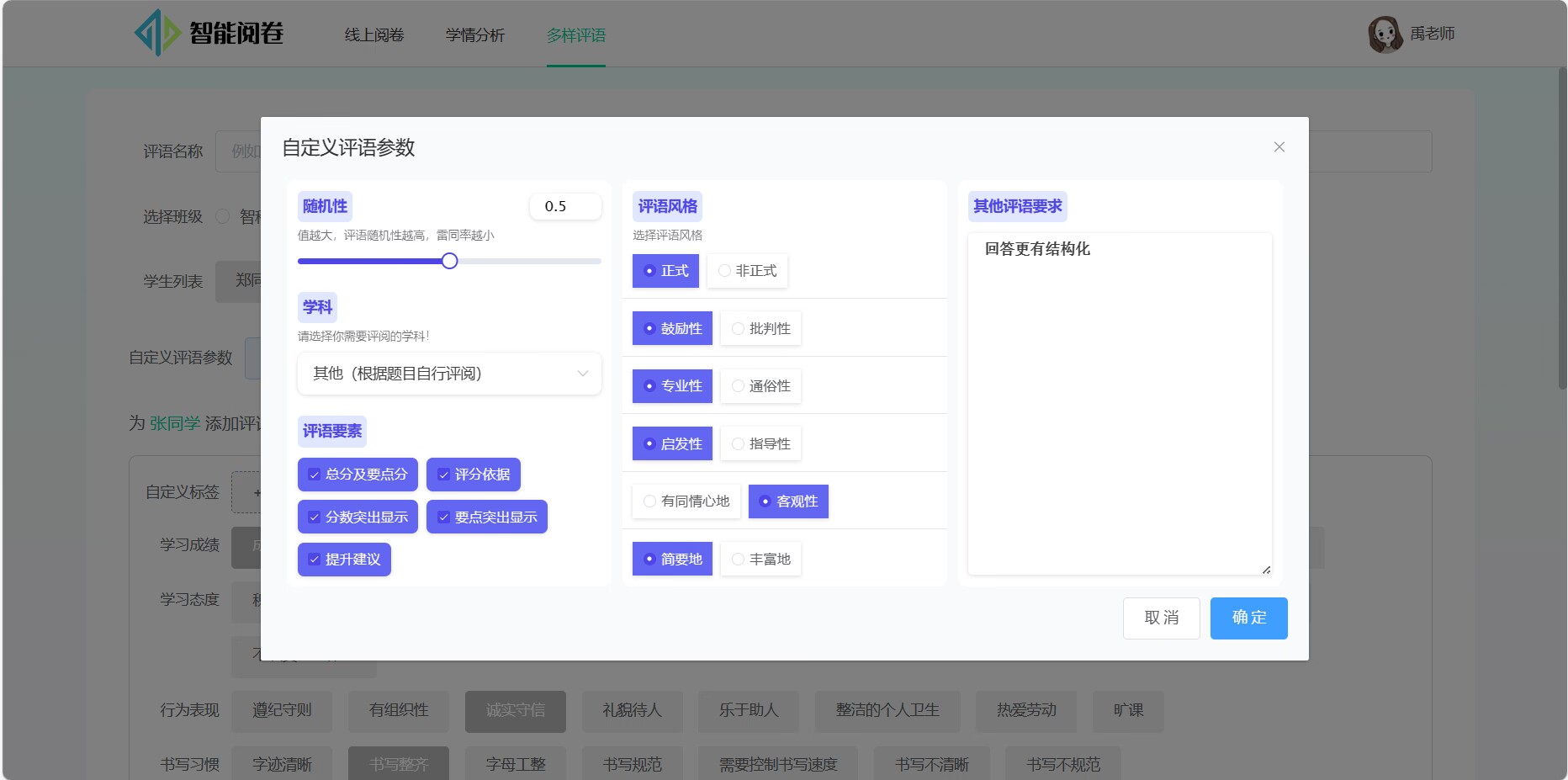
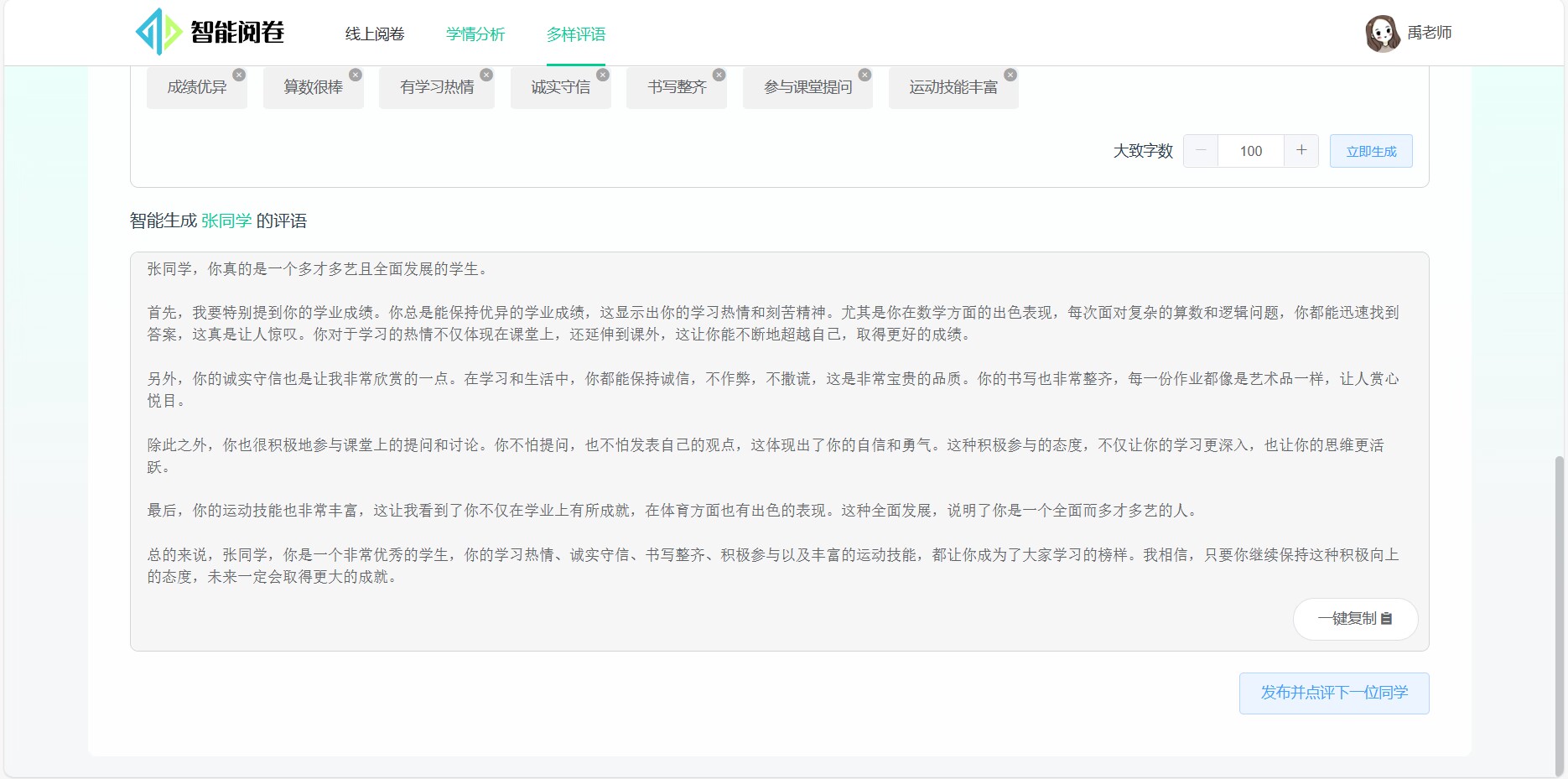
生成评语:

此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。







