

代码拉取完成,页面将自动刷新
title: HBase 快速入门
date: 2020-02-10 14:27:39
categories:
- 数据库
- 列式数据库
- HBase
tags:
- 数据库
- 列式数据库
- 大数据
- HBase
permalink: /pages/7ab03c/
在介绍 HBase 之前,我们不妨先了解一下为什么需要 HBase,或者说 HBase 是为了达到什么目的而产生。
在 HBase 诞生之前,Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
Hadoop 的缺陷在于:它只能执行批处理,并且只能以顺序方式访问数据。这意味着即使是最简单的工作,也必须搜索整个数据集,即:Hadoop 无法实现对数据的随机访问。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来同时解决海量数据存储和随机访问的问题,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
注:数据结构分类:
- 结构化数据:即以关系型数据库表形式管理的数据;
- 半结构化数据:非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档、Email 等;
- 非结构化数据:没有固定模式的数据,如 WORD、PDF、PPT、EXL,各种格式的图片、视频等。
HBase 是一个构建在 HDFS(Hadoop 文件系统)之上的列式数据库。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。
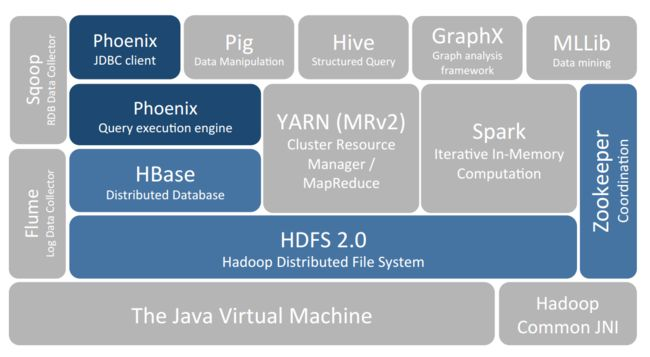
HBase 的核心特性如下:
HBase 的其他特性
根据上一节对于 HBase 特性的介绍,我们可以梳理出 HBase 适用、不适用的场景:
HBase 不适用场景:
HBase 适用场景:
一言以蔽之——HBase 适用的场景是:实时地随机访问超大数据集。
HBase 的典型应用场景
前面已经提及,HBase 是一个列式数据库,其数据模型和关系型数据库有所不同。其数据模型的关键术语如下:
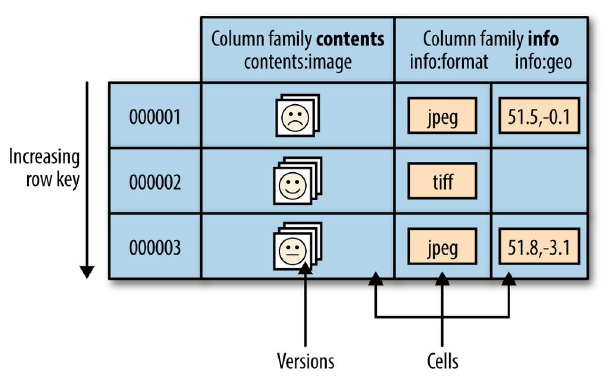
| RDBMS | HBase |
|---|---|
| RDBMS 有它的模式,描述表的整体结构的约束 | HBase 无模式,它不具有固定列模式的概念;仅定义列族 |
| 支持的文件系统有 FAT、NTFS 和 EXT | 支持的文件系统只有 HDFS |
| 使用提交日志来存储日志 | 使用预写日志 (WAL) 来存储日志 |
| 使用特定的协调系统来协调集群 | 使用 ZooKeeper 来协调集群 |
| 存储的都是中小规模的数据表 | 存储的是超大规模的数据表,并且适合存储宽表 |
| 通常支持复杂的事务 | 仅支持行级事务 |
| 适用于结构化数据 | 适用于半结构化、结构化数据 |
| 使用主键 | 使用 row key |
| HDFS | HBase |
|---|---|
| HDFS 提供了一个用于分布式存储的文件系统。 | HBase 提供面向表格列的数据存储。 |
| HDFS 为大文件提供优化存储。 | HBase 为表格数据提供了优化。 |
| HDFS 使用块文件。 | HBase 使用键值对数据。 |
| HDFS 数据模型不灵活。 | HBase 提供了一个灵活的数据模型。 |
| HDFS 使用文件系统和处理框架。 | HBase 使用带有内置 Hadoop MapReduce 支持的表格存储。 |
| HDFS 主要针对一次写入多次读取进行了优化。 | HBase 针对读/写许多进行了优化。 |
| 行式数据库 | 列式数据库 |
|---|---|
| 对于添加/修改操作更高效 | 对于读取操作更高效 |
| 读取整行数据 | 仅读取必要的列数据 |
| 最适合在线事务处理系统(OLTP) | 不适合在线事务处理系统(OLTP) |
| 将行数据存储在连续的页内存中 | 将列数据存储在非连续的页内存中 |
列式数据库的优点:
列式数据库的缺点:
连接 HBase
在 HBase 安装目录的 /bin 目录下执行 hbase shell 命令进入 HBase 控制台。
$ ./bin/hbase shell
hbase(main):001:0>
输入 help 可以查看 HBase Shell 命令。
创建表
可以使用 create 命令创建一张新表。必须要指定表名和 Column Family。
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
列出表信息
使用 list 命令来确认新建的表已存在。
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
可以使用 describe 命令可以查看表的细节信息,包括配置信息
hbase(main):003:0> describe 'test'
Table test is ENABLED
test
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE =>
'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'f
alse', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE
=> '65536'}
1 row(s)
Took 0.9998 seconds
向表中写数据
可以使用 put 命令向 HBase 表中写数据。
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
一次性扫描表的所有数据
使用 scan 命令来扫描表数据。
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds
查看一行数据
使用 get 命令可以查看一行表数据。
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds
禁用表
如果想要删除表或修改表设置,必须先使用 disable 命令禁用表。如果想再次启用表,可以使用 enable 命令。
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds
删除表
使用 drop 命令可以删除表。
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
退出 HBase Shell
使用 quit 命令,就能退出 HBase Shell 控制台。
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。






